Acting Optimally in Partially Observable Stochastic Domains
Classic Paper Award, AAAI-94
Anthony R. Cassandra
Brown University
MCC
St. Edwards University
University of Texas
Pronto, LLC
Leslie Pack Kaelbling
Brown University
Massachusetts Institute of Technology
Michael L. Littman
Brown University
Duke University
AT&T
Rutgers University
Brown University
Outline
The AAAI-94 Paper
A Retrospective
N/A
The Model: POMDP
P
artially
O
bservable
M
arkov
D
ecision
P
rocess
Probabilistic model for sequential decision making.
Discrete time epochs.
Discrete set of states.
Discrete set of actions.
Discrete set of observations.
Immediate reward/cost structure.
Important to not assume everyone knows what a POMDP is.
Related Models
Markov
Models
Do we have control
over the state transitions?
NO
YES
Are the states
completely
observable?
YES
Markov Chain
MDP
Markov Decision Process
NO
HMM
Hidden Markov Model
POMDP
Partially Observable
Markov Decision Process
Zzz
Zzz
Zzz
N/A
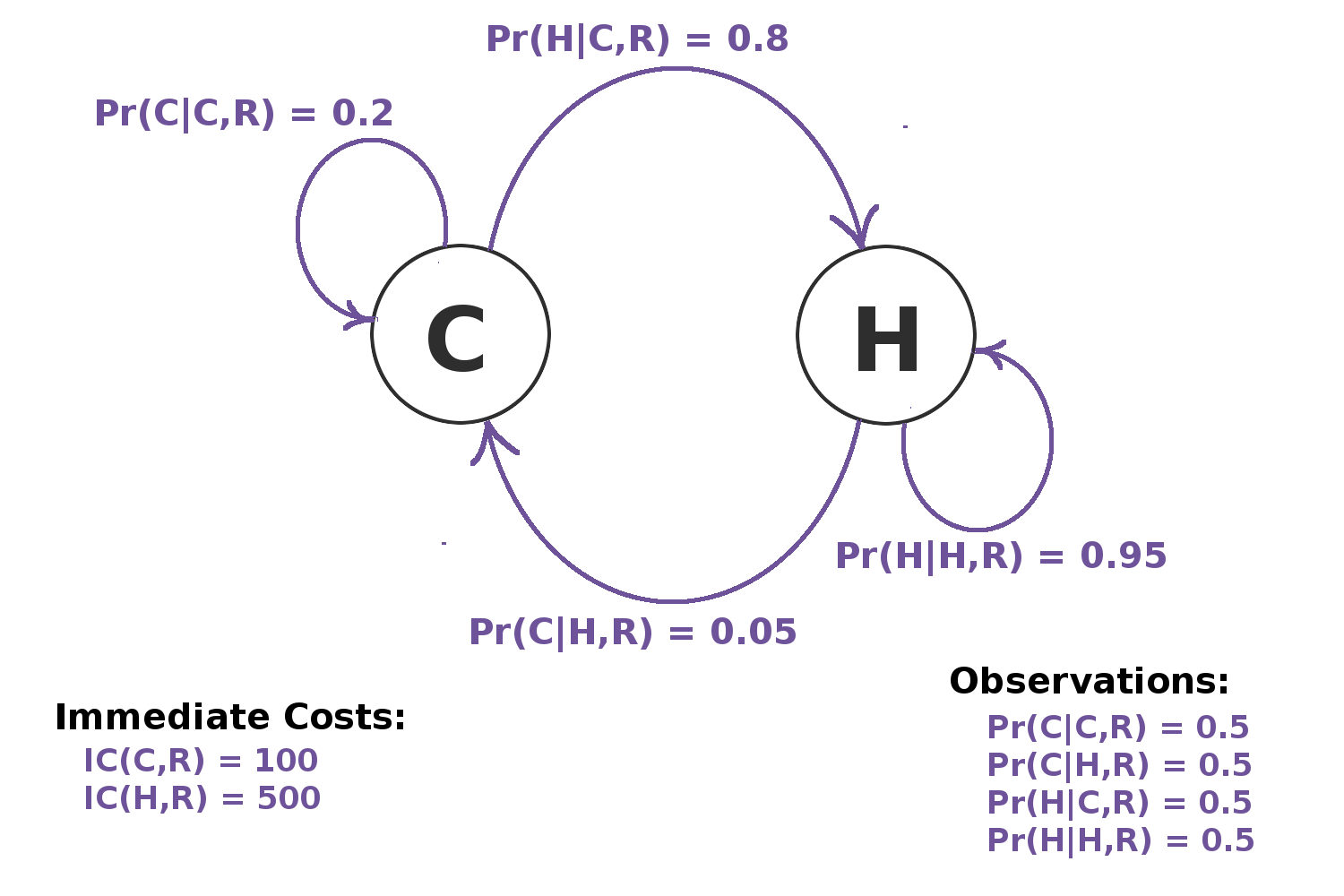
POMDP Example: Health Care
Suppose time scale is every 3 months we need to make a decision.
POMDP Action: Radiation Treatment
May change patient's state, but does not provide information and has a very high cost.
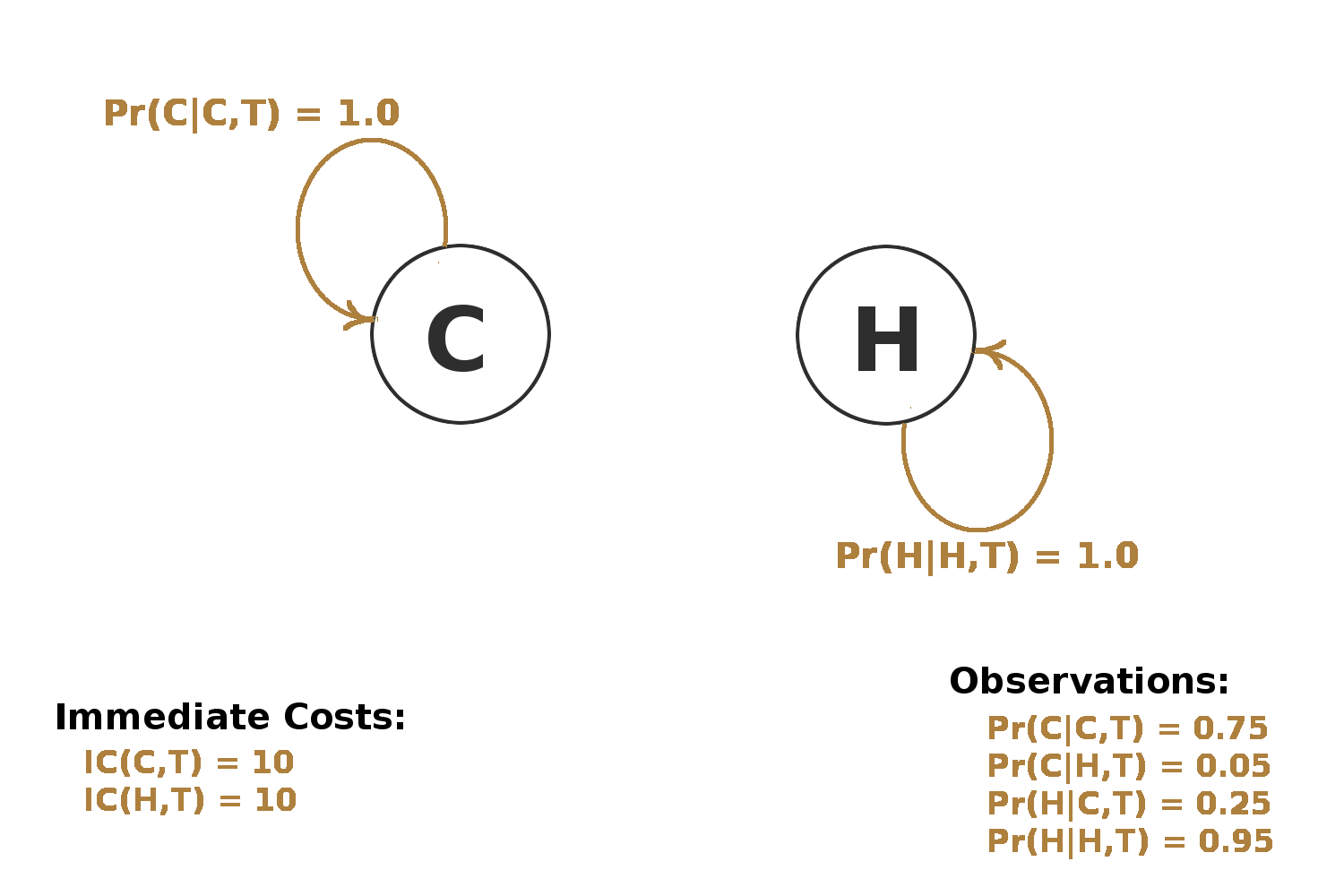
POMDP Action: Non-invasive Tests
Does not change patient's state, but provides information.
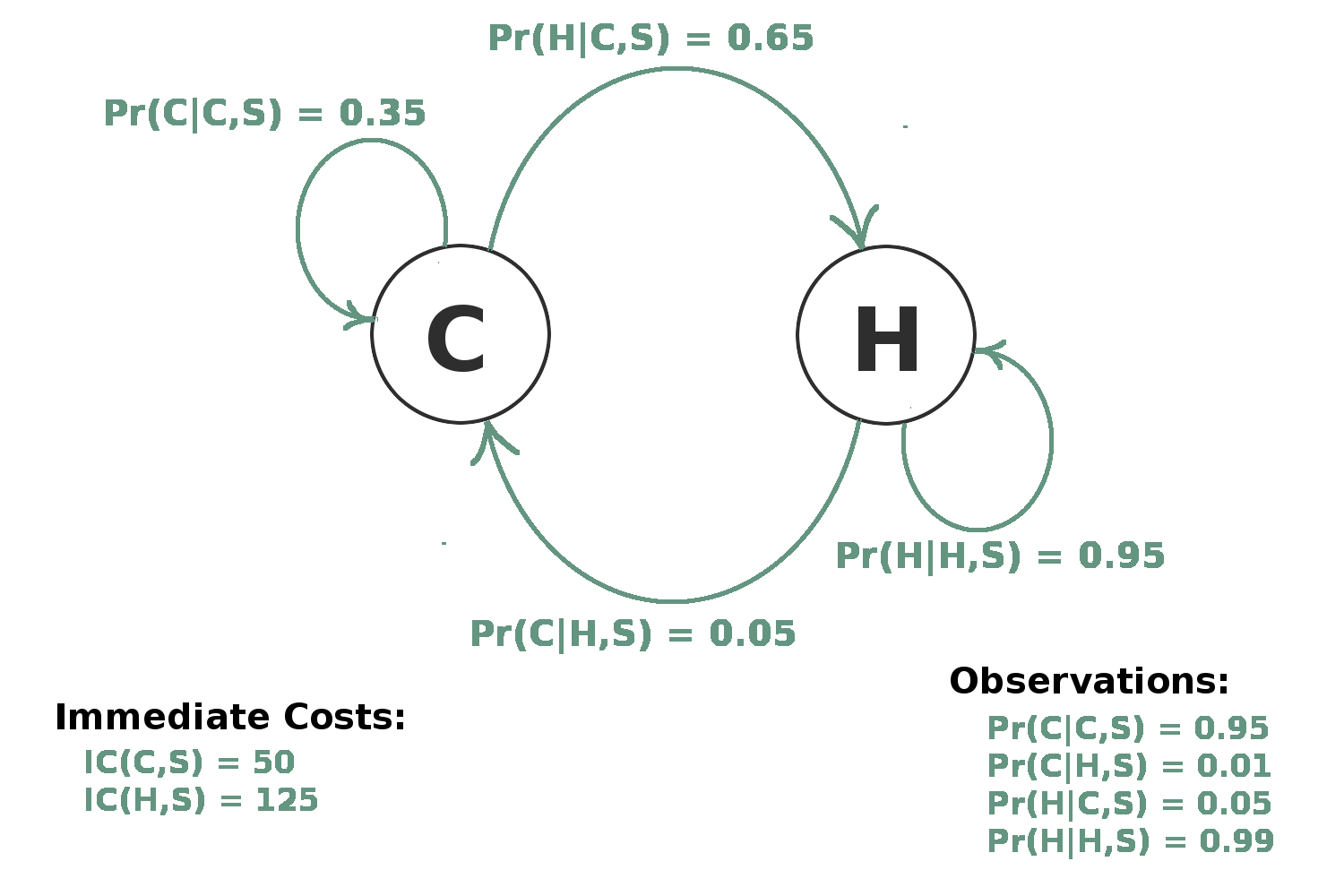
POMDP Action: Surgery
Can both provide information and change state.
Provides better information, but cost is higher.
Less likely to cure than radiation treatment.
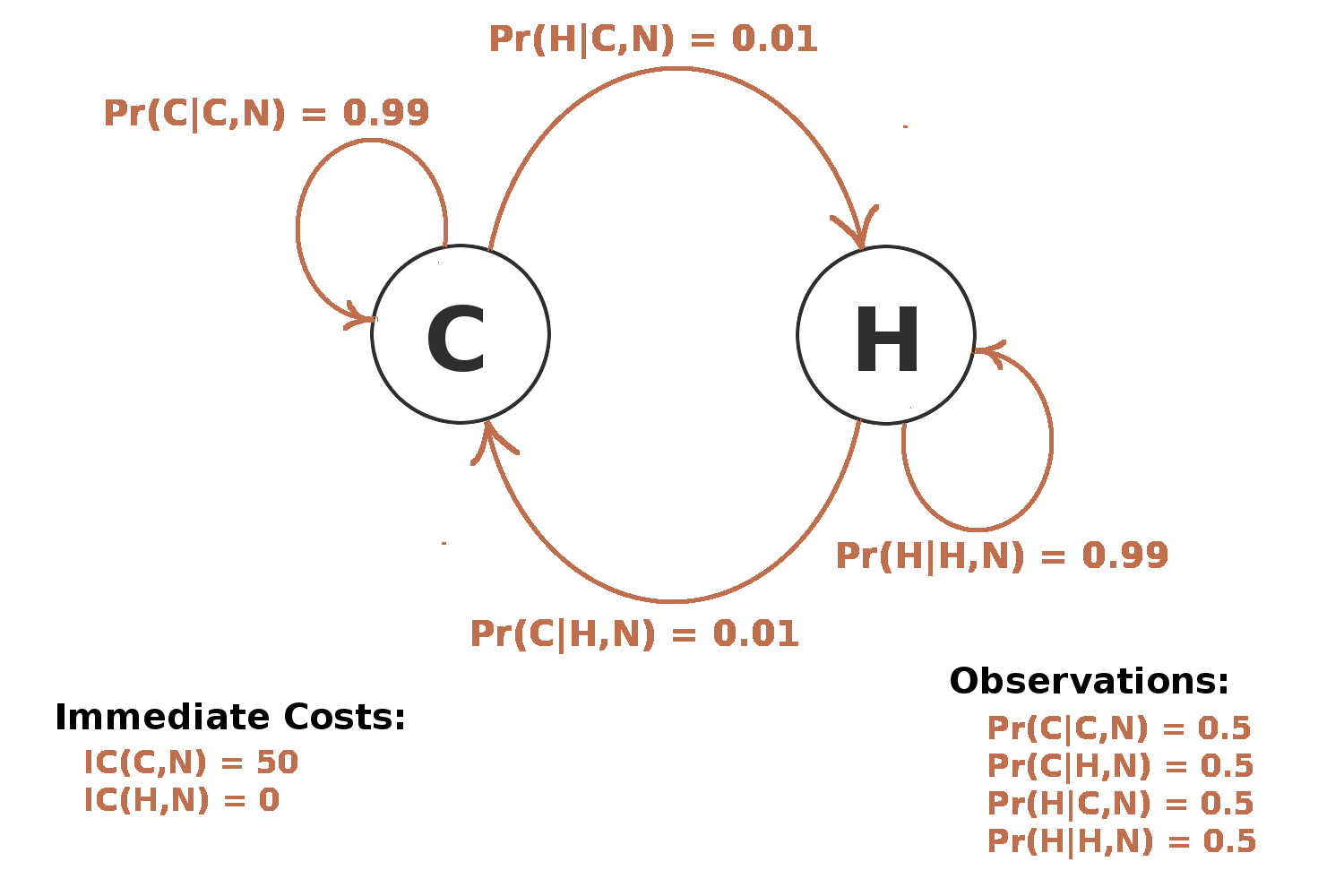
POMDP Action: Do Nothing
Doing nothing always an option, but might have high cost if patient not healthy.
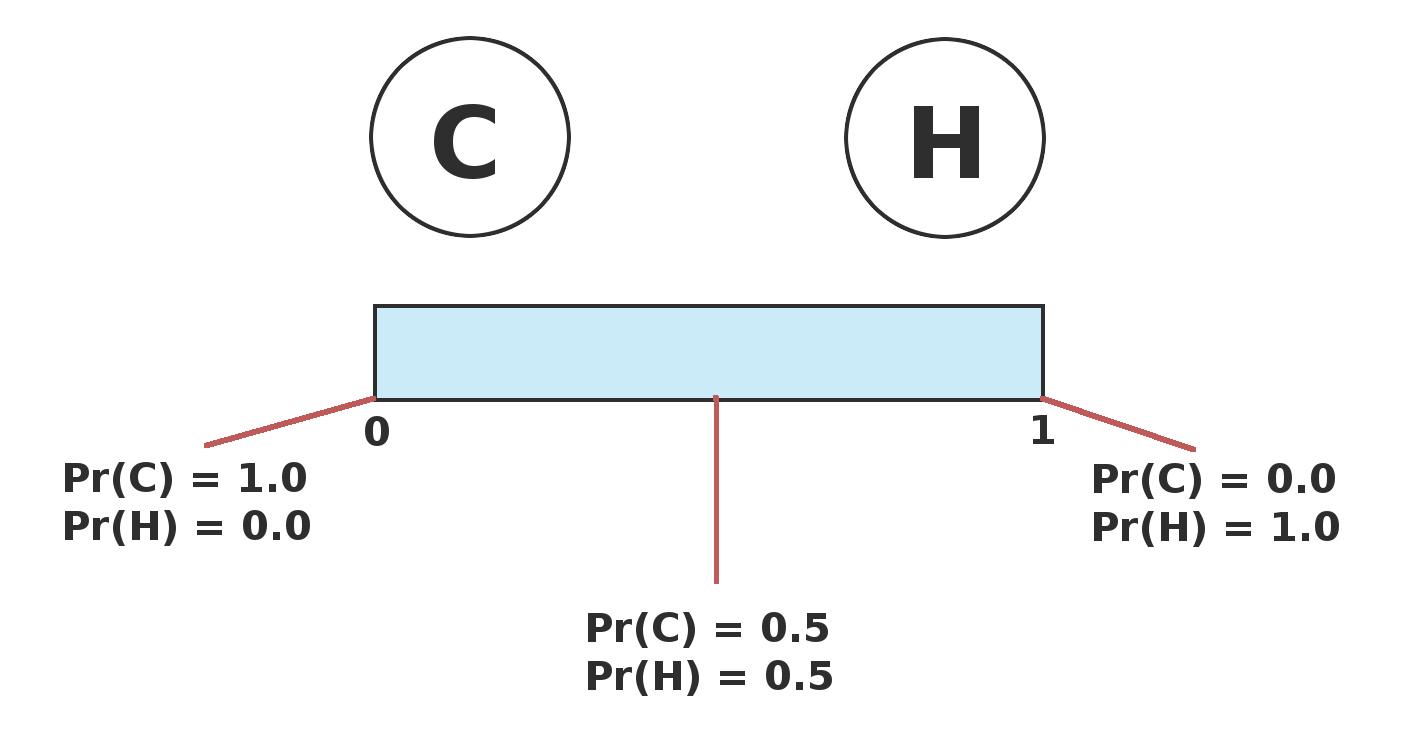
Belief States
Solution that maps states to actions not possible.
Mapping observations to actions not possible.
Techniques use probability distribution over states.
Bayes' Rule can be used to update the belief state.
Zzz
Zzz
Zzz
N/A
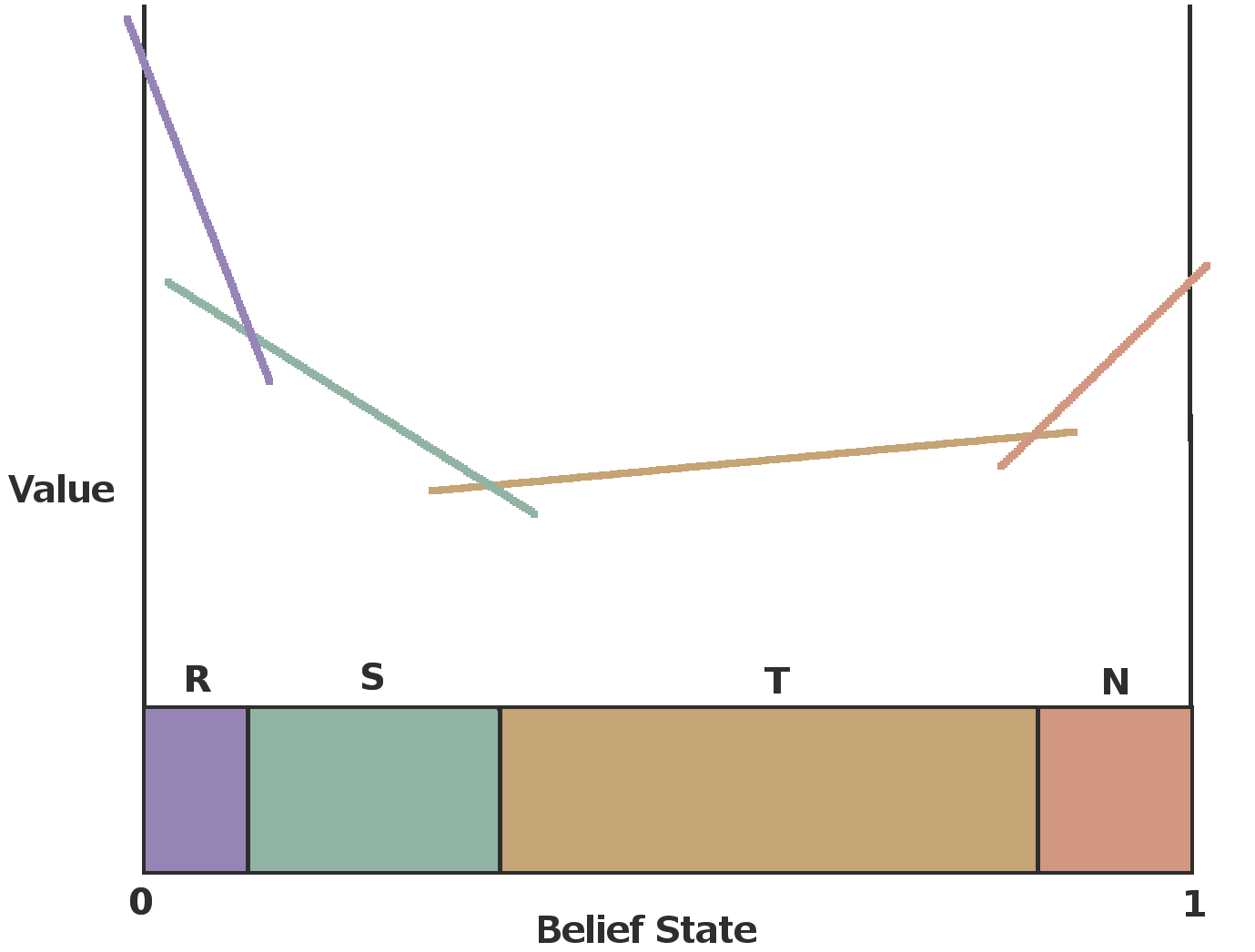
Solutions Over Belief Space
How good is this solution?
Is there a better solution?
Need to find the value at all (infinite) belief points.
Zzz
Previous Work
Most prior work in Operations Research community.
Markov property of belief states (Ästrom, 1965).
Optional solution properties and first algorithm (Sondik, 1971).
Finite Grid Approximations (Lovejoy, 1991)
Applications:
medical diagnosis, machine maintenance, fisheries, questionnaire design, moving target search, search and rescue, target identification, corporate policy, internal auditing, health-care policy making.
Mapping states to actions cannot work, so need
Zzz
Zzz
N/A
Solution Properties and Techniques
Previous exact algorithm identified optimal solution as dividing belief space into a finite number of linear regions.
Algorithms just need a way to enumerate the regions.
Zzz
Zzz
Zzz
N/A
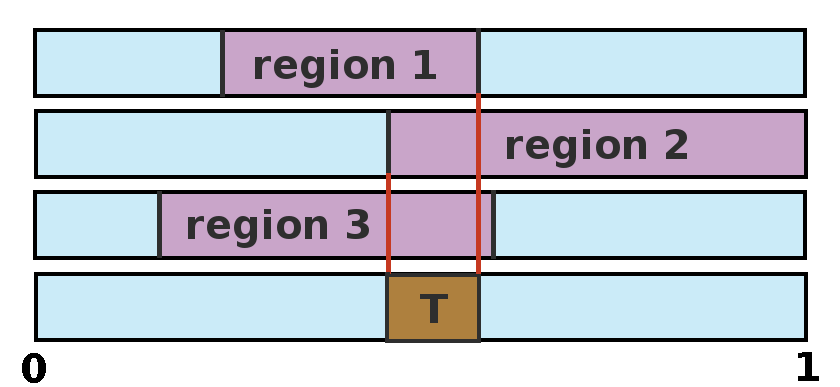
Previous Algorithm (Sondik, 1971)
Defined linear regions for a given point.
Bounds of regions define points for next regions.
Regions defined are very conservative.
zzz
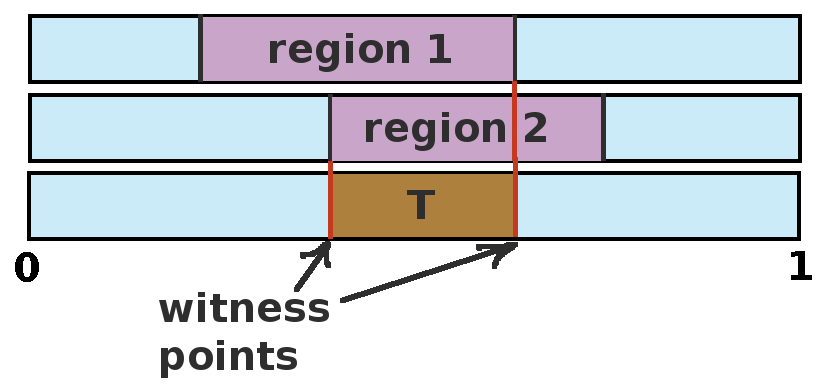
Witness Algorithm (Cassandra,
et al.
, 1994)
Computes regions for each action separately, then combines.
Defines simpler regions by ignoring exact values at boundaries.
Looks for points where current value can be improved.
Exploits region structure better.
Eliminates redundant work.
A Retrospective
Alternative Solution Techniques
Model framework is very powerful.
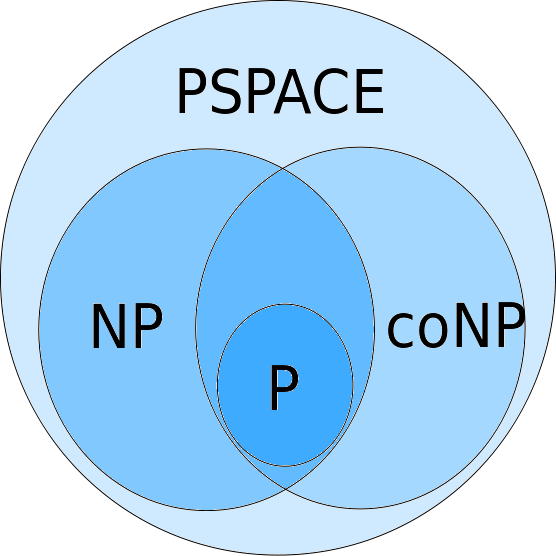
Exact algorithms too computationally complex (PSPACE Complete).
Point-based (approximate) methods proved more useful.
Zzz.
Model/Problem Exposure
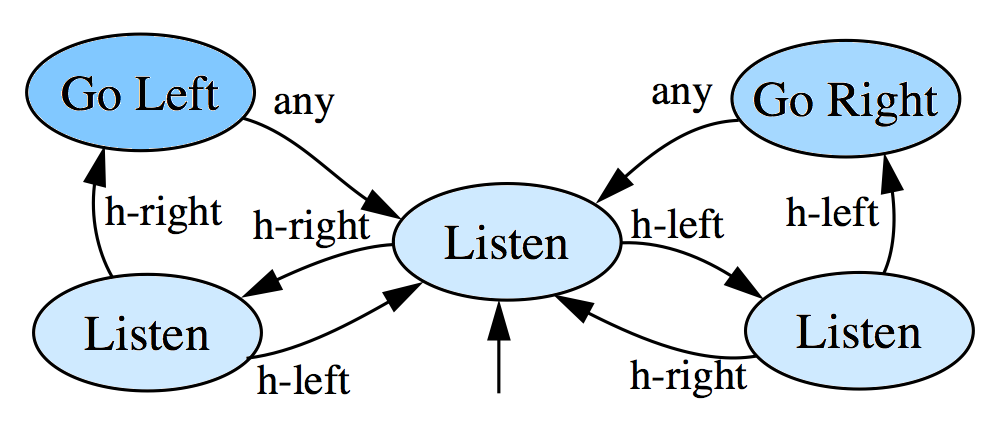
Tiger problem.
Solution structures: policy graphs.
POMDPs becoming "core" in AI: AIMA Text (Russell & Norvig).
Zzz.
Road to Better Implementations
Previously, code non-existent, hard to find or not runnable.
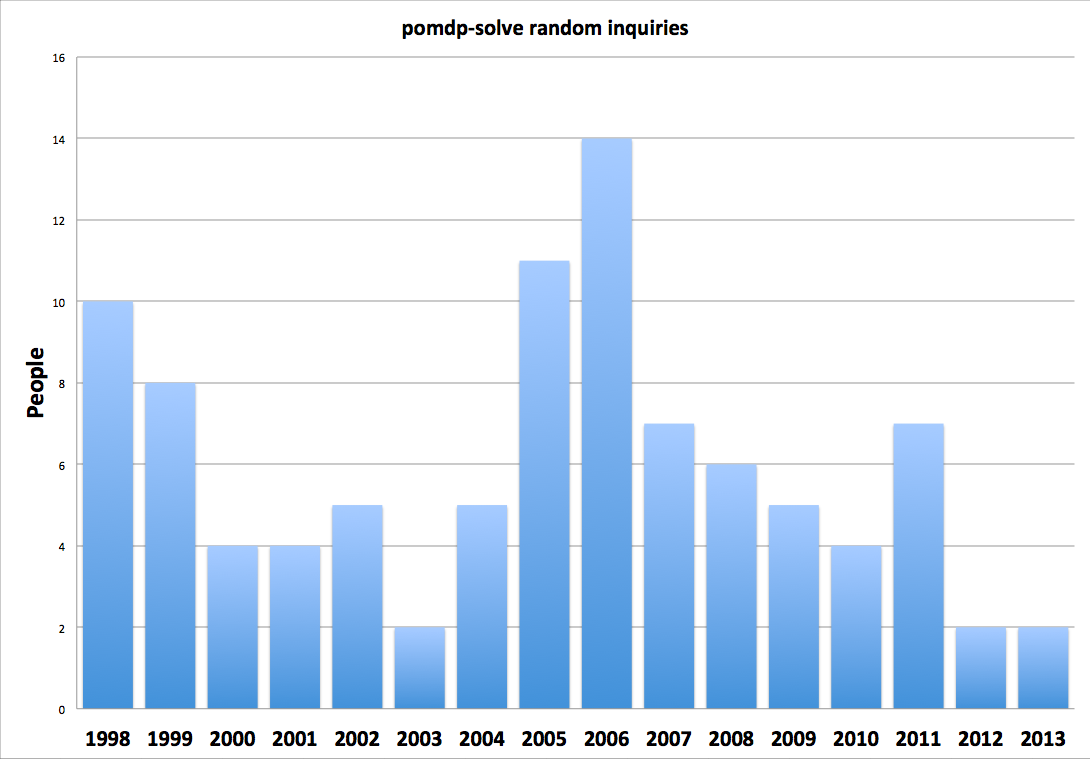
pomdp-solve
still useful for some researchers.
Better implementations and toolkits are now available.
Zzz.
More Application Areas
Robotics and planning.
Spoken dialog systems.
Unmanned aircraft collision avoidance.
Human decision making and aides (cognitive science).
Zzz
Zzz
Zzz
N/A
The End